Bootstrapping MariaDB cluster
If no node is active, i.e., there is no cluster, the first node must be bootstrapped to start the cluster. Bootstrapping a node makes the node the main component of the cluster.
Attention
Follow this section only if you are using the built-in MariaDB cluster. If your deployment uses an external database, you can skip this section.
The first node can de bootstrapped using the following command:
sudo cm-cluster-manage --bootstrap-node
Warning
Only the first node should be bootstrapped. All other nodes will automatically connect to the cluster when they are started.
As long as the cluster is active, i.e., the majority of the nodes are connected to the cluster, the cluster will be functional and new nodes can be added and removed. If the last node from the cluster is stopped, the cluster is no longer active and must be bootstrapped again.
The node which is bootstrapped will be used as the base dataset, i.e., all other nodes will receive all settings, certificates etc. from the bootstrapped node. It is therefore important that the node that was removed last from the cluster is the node that should be bootstrapped because it will contain the latest updates.
Note
The node that was removed last from the cluster is the node that should be bootstrapped.
Every node keeps track whether it is safe to bootstrap the node. If a node is removed from an active cluster, the safe to bootstrap variable is set to 0 to indicate that it is not safe to bootstrap from this node. If a node is not safe to be bootstrapped, the following message will be printed when trying to bootstrap the node:
*********************************************************************
* Warning: It is not safe to bootstrap this node. Please bootstrap *
* the node that was last removed from the cluster. To force *
* boostrapping this node, use the command --force-safe-to-bootstrap *
* before bootstrapping this node. *
*********************************************************************
Note
The safe to bootstrap value can be retrieved with the command:
sudo cm-cluster-manage --safe-to-bootstrap
Under certain circumstances it might be needed to override the safe to bootstrap value (see problem solving section below). safe to bootstrap can be set to 1 with the command:
sudo cm-cluster-manage --force-safe-to-bootstrap
Check node status
The node status can be checked using the following command:
sudo cm-cluster-manage --show-cluster-status
The output of the --show-cluster-status command should look like:
+--------------------------+--------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------+
| wsrep_cluster_conf_id | 1 |
| wsrep_cluster_size | 1 |
| wsrep_cluster_state_uuid | 8348d5ea-5664-11e7-8628-262d8bf5ad3d |
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
| wsrep_gcomm_uuid | 8347b5eb-5664-11e7-9459-667d2cc2032f |
| wsrep_last_committed | 0 |
| wsrep_local_state_uuid | 8348d5ea-5664-11e7-8628-262d8bf5ad3d |
| wsrep_ready | ON |
+--------------------------+--------------------------------------+
After bootstrapping the first node, wsrep_cluster_size should be set to 1.
Check back-end log
The back-end log should be checked to see whether back-end starts without any errors:
sudo tail -f /var/log/ciphermail-gateway-backend.log
The following line should be visible in the logs if the back-end started successfuly:
SMTP Service started plain:10025//127.0.0.1
Press CTRL+C to exit.
Starting other nodes
Once the first node is bootstrapped, the other nodes can be started in the normal way either by rebooting the gateway or by using the following command:
sudo cm-cluster-manage --restart-node
Check node status
The node status can be checked using the following command:
sudo cm-cluster-manage --show-cluster-status
The output of the --show-cluster-status command should look like:
+--------------------------+--------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------+
| wsrep_cluster_conf_id | 2 |
| wsrep_cluster_size | 2 |
| wsrep_cluster_state_uuid | 8348d5ea-5664-11e7-8628-262d8bf5ad3d |
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
| wsrep_gcomm_uuid | ea4e26e9-5678-11e7-bc53-3e334c415aa8 |
| wsrep_last_committed | 4 |
| wsrep_local_state_uuid | 8348d5ea-5664-11e7-8628-262d8bf5ad3d |
| wsrep_ready | ON |
+--------------------------+--------------------------------------+
wsrep_cluster_size should be set to the number of nodes that have been started.
Check back-end log
The back-end log should be checked to see whether back-end starts without any errors:
sudo tail -f /var/log/ciphermail-gateway-backend.log
The following line should be visible in the logs if the back-end started successfuly:
SMTP Service started plain:10025//127.0.0.1
Press CTRL+C to exit.
Recovery
In a fully functional cluster, every node from the cluster can communicate with every other node (see figure cluster-fully-functional-figure).
In a three node cluster, different issue can influence the stability of the cluster. For example one or more nodes can fail, the network connection between nodes can fail, a node can be manually stopped etc. In the remainder of this section a number of failure scenarios will be discussed. The impact of these failures on the status of the cluster will be discussed and what steps should be taken to recover from these failures.
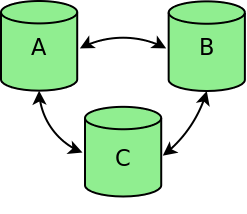
Cluster fully functional
Failure scenarios
One node is gracefully stopped
If one node is stopped in a controlled way, for example for maintenance or because of a reboot, the node is gracefully removed from the cluster. The cluster size is reduced to a two node cluster (see figure cluster-one-node-stopped-figure). Nodes B and C will continue to function and will replicate all changes between the two nodes. If node A is restarted, node A will automatically connect to the other two nodes and will be synchronized to make the node up-to-date again.
The stopped node can be restarted by rebooting the gateway or by using the restart command (see section Starting other nodes).
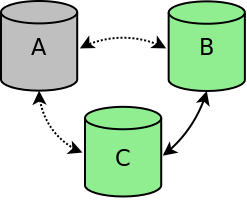
Cluster one node stopped
Two nodes are gracefully stopped
If node A and B are stopped in a controlled way, for example for maintenance or because of a reboot, the nodes are gracefully removed from the cluster. The cluster size is reduced to a one node cluster (node C). If node A or B is restarted, the node will automatically connect to the other nodes and will be synchronized to make the node up-to-date again.
The stopped nodes can be restarted by rebooting the gateway or by using the restart command (see section Starting other nodes).
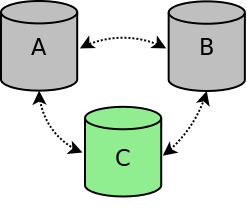
Cluster two nodes stopped
All nodes are gracefully stopped
If all nodes are gracefully stopped, the cluster is no longer active and must be bootstrapped again. The node that was last removed from the cluster should be bootstrapped and the other nodes should be started.
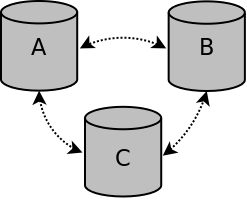
Cluster all nodes stopped
One node is terminated
If node A is terminated in an ungraceful way, for example the node crashed or there was a power outage, the node is removed from the cluster. Because the two other nodes still have a quorum (2 out of 3), the cluster is still active (see figure cluster-one-node-terminated-figure). Nodes B and C will continue to function and will replicate all changes between the two nodes. If node A is restarted, node A will automatically connect to the other two nodes and will be synchronized to make the node up-to-date again.
Node A can be reconnected by rebooting the gateway or by using the restart command (see section Starting other nodes).
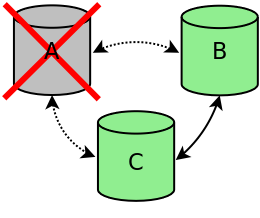
Cluster one node terminated
Two nodes are terminated
If nodes A and B are terminated in an ungraceful way, for example the nodes crash or there was a power outage, node A and B are removed from the cluster. Because node C no longer has quorum (1 out of 3), node C will no longer accept connections.
If node A or node B is restarted, the cluster will not automatically be restored because none of the nodes know which node has the most up-to-date data. Node C only knows that it could no longer communicate with node A and node B. Node C however does not know whether the communication failure was caused by crashing of node A and B or because of network issues. Because the cluster is not automatically restored, the cluster must be bootstrapped. Node C should be bootstrapped and the other nodes should be started. Because the cluster was not gracefully shutdown, node C is not allowed to be bootstrapped (i.e., safe to bootstrap is set to 0). Before bootstrapping node C, safe to bootstrap should therefore be forced with the following command:
sudo cm-cluster-manage --force-safe-to-bootstrap
Node C can now be bootstrapped.
Note
Make sure node A and node B are really down before forcing node C to bootstrap and that the issue was not caused by some network failure between node C and the other two nodes. Otherwise you might end up with two separate clusters: one cluster with only node C and another cluster with node A and node B.
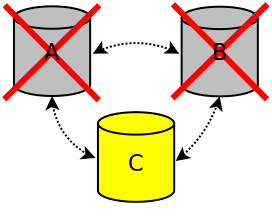
Cluster two nodes terminated
All nodes are terminated
If all nodes are terminated in an ungraceful way, for example the nodes crash or there was a power outage, in most cases the cluster can automatically restore itself when the nodes are started again. If the cluster is not automatically restored after restarting the nodes, the cluster should be manually bootstrapped.
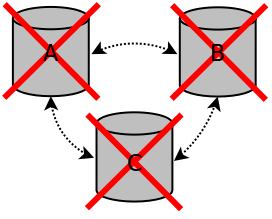
Cluster all nodes terminated
Connection failure between one node and the other nodes
If node A can no longer communicate with node B and C, because for example there is a network failure node A’s data center, the node is removed from the cluster. The node will no longer accept incoming connections. Because the two other nodes still have a quorum (2 out of 3), the cluster is still active. Nodes B and C will continue to function and will replicate all changes between the two nodes. If the connection between node A and the other nodes is restored, node A will automatically connect to the other two nodes and will be synchronized to make the node up-to-date again.
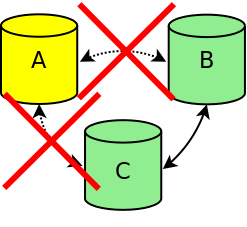
Cluster one node connection failure
Connection failure between all nodes
If a complete network failure disrupts all communication between all nodes, all nodes stop accepting incoming connections. If network communication is restored, the cluster should be restored automatically. If the cluster is not automatically restored, the cluster should be manually bootstrapped.
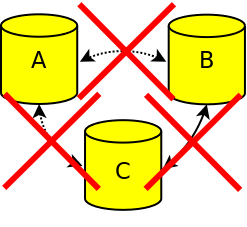
Cluster all nodes connection failure
Recovery procedure
To recover a non-functional cluster, it’s important to know whether all nodes failed or whether only one or two nodes failed.
Check cluster status
To check the cluster status, execute the following command:
sudo cm-cluster-manage --show-cluster-status
The wsrep_cluster_size varaible shows the number of nodes that are part of the cluster.
+--------------------------+--------------------------------------+ | Variable_name | Value | +--------------------------+--------------------------------------+ | wsrep_cluster_conf_id | 3 | | wsrep_cluster_size | 3 | | wsrep_cluster_state_uuid | 7159b315-ed8a-11ed-b66b-82b08426f1d2 | | wsrep_cluster_status | Primary | | wsrep_connected | ON | | wsrep_gcomm_uuid | 7159632c-ed8a-11ed-b181-e6e4c001f53a | | wsrep_last_committed | 0 | | wsrep_local_state_uuid | 7159b315-ed8a-11ed-b66b-82b08426f1d2 | | wsrep_ready | ON | +--------------------------+--------------------------------------+ +-----------------------+---------------------------------------------------------------+ | Variable_name | Value | +-----------------------+---------------------------------------------------------------+ | wsrep_cluster_address | gcomm://node1.example.com,node2.example.com,node3.example.com | | wsrep_cluster_name | ciphermail | | wsrep_node_address | node1.example.com | | wsrep_node_name | node1.example.com | +-----------------------+---------------------------------------------------------------+
For a fully functional cluster with all three (3) nodes active, wsrep_cluster_size should be set to 3.
If MariaDB is not running on the current node, the following error message will be shown:
ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2)
Repeat the above procedure for all three nodes.
Recover cluster
If all three nodes are active no recovery is required. If at least one node is down, a recovery is needed.
The steps to take to fully recover the cluster, depends on whether all nodes are down or whether some nodes are down.
Only some nodes are down
if only some nodes are down, try to restart the failing node.
sudo cm-cluster-manage --restart-node
Alternatively, you can reboot the server
Check the cluster status to see if the node has come up:
sudo cm-cluster-manage --show-cluster-status
All nodes are down
If all nodes are down, i.e., every node reports that MySQL (MariaDB) is not running, the cluster must be bootstrapped.
Only the node that last left the cluster can be bootstrapped. To find out whether a node can be bootstrapped, execute the following command:
sudo cm-cluster-manage --safe-to-bootstrap
If the result is 1, the node is safe to bootstrap. If the result is 0 the node is not safe to bootstrap.
Repeat the above step on all nodes until you find a node which is safe to bootstrap.
Important
No node is safe for bootstrapping?
If no node is safe to bootstrap, one node should be forced to be bootstrapped. This can happen if all nodes from a cluster were terminated, for example because of a power failure. In that case you need to find out which node has the most recent changes and force that node to be bootstrapped.
To find out which node should be bootstrapped, use the following procedure:
Execute the following commands:
sudo killall -9 mysqld
sudo -u mysql /bin/mysqld_safe --wsrep-recover
sudo killall -9 mysqld
The recovery process logs the recovery process to the MariaDB log file. To get the recovery position, grep the log file:
sudo grep 'WSREP: Recovered position' /var/log/mariadb/mariadb.log | tail -1
The recovery position is reported at the end of the line. The following example shows that the recovery position for the node is 0:
WSREP: Recovered position: 7159b315-ed8a-11ed-b66b-82b08426f1d2:0
Repeat the above procedure for every node.
The node for which the recovered position is the highest is the node which should be bootstrapped.
Example:
WSREP: Recovered position: 7159b315-ed8a-11ed-b66b-82b08426f1d2:0 WSREP: Recovered position: 39cb5fa9-ed9c-11ed-a43f-9e6583adc15d:1 WSREP: Recovered position: d89c79f4-b308-11e9-9931-8f96b3cc57b2:2
In the above example, the node for which the recovered position ends with :2 should be bootstrapped because the recovered position is the highest.
Note: If multiple nodes have the same recovered position, select one of the nodes with the higest value.
To force the node with the highest recovered position to be bootstrapped, execute the following command on the node to be bootstrapped:
sudo cm-cluster-manage --force-safe-to-bootstrap
Boostrap node
Warning
Only bootstrap one node!
On the node which is allowed to be bootstrapped, issue the following command to boostrap the node:
Stop MariaDB:
sudo systemctl stop mariadb
if that hangs, press CTRL-C and kill the process:
sudo killall -9 mysqld
Bootstrap the node
sudo cm-cluster-manage --bootstrap-node
To check whether the node was successfully bootstrapped, check the status:
sudo cm-cluster-manage --show-cluster-status
wsrep_cluster_size should be set to 1 and wsrep_ready should be set to ON
+--------------------------+--------------------------------------+ | Variable_name | Value | +--------------------------+--------------------------------------+ | wsrep_cluster_conf_id | 1 | | wsrep_cluster_size | 1 | | wsrep_cluster_state_uuid | 7159b315-ed8a-11ed-b66b-82b08426f1d2 | | wsrep_cluster_status | Primary | | wsrep_connected | ON | | wsrep_gcomm_uuid | 39cb5fa9-ed9c-11ed-a43f-9e6583adc15d | | wsrep_last_committed | 0 | | wsrep_local_state_uuid | 7159b315-ed8a-11ed-b66b-82b08426f1d2 | | wsrep_ready | ON | +--------------------------+--------------------------------------+
Start the other nodes
Once the node is successfully bootstrapped, the other nodes can be restarted:
Stop MariaDB:
sudo systemctl stop mariadb
if that hangs, press CTRL-C and kill the process:
sudo killall -9 mysqld
sudo cm-cluster-manage --restart-node
To check whether the node was successfully started, check the status:
sudo cm-cluster-manage --show-cluster-status
Repeat the above procedure for the other node.
If the two nodes are restarted, the cluster size should be set to 3
sudo cm-cluster-manage --show-cluster-status
::
+--------------------------+--------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------+
| wsrep_cluster_conf_id | 3 |
| wsrep_cluster_size | 3 |
Updates
Warning
If CipherMail is configured as an HA cluster, always update packages on one node at a time. Start with the node that was used to set up the cluster. Wait updating the other node(s) until the node that was updated is back online and that the cluster status reports that all three nodes are active again.
Since CipherMail Gateway version 5 and Webmail version 4, various configuration and automation tasks are performed using Ansible. The Ansible playbook is kicked off at the end of every CipherMail package upgrade. To ensure that new Ansible configuration only manages the CipherMail software version it was designed for, the automated playbook run only targets the local host, i.e. the node you are currently upgrading. This way you can safely upgrade all nodes one after the other and be assured that any configuration changes will be correctly applied.
The downside of this approach is that it is not safe to manually run the
playbook against a partially upgraded cluster. Running $ sudo
cm-run-playbook without any arguments causes the playbook to be executed
against the local host. If you need to run the playbook against all hosts, use
the --all-hosts flag. Don’t do this with a partially upgraded cluster!