This posting is a bit different from the usual articles on our blog. Instead of telling you how you can use CipherMail to protect your email, this article will give some insight in how we use our products ourselves as a way of quality control and testimonial advertising. It's called eating our own dog food, after the president of a pet food company who was said to eat his own dog food at shareholder meetings.
We’ve been telling our customers for a long time how they should implement the CipherMail Email Encryption Gateway in their existing email infrastructure. Our usual advice is to use a hairpin design where mail flows in through the existing mail server, gets forwarded to the CipherMail Gateway which does all the cryptographic operations, before returning it to the same mail server for delivery. We’ve been recommending this method since at least December 2010:

So that’s how we recommend it to most of our customers, but we haven’t been using it ourselves this way until a few weeks ago. We did use CipherMail Gateway (and also Webmail) however, but more in a ‘pipeline’ configuration where outgoing mail was sent from mail server → gateway → Internet and incoming mail was received from Internet → gateway → mail server. The downside of this approach is that it makes both the gateway and the mail server responsible for spam filtering, the former for incoming and the latter for outgoing mail. There is also no central point where mail is queued or access control is handled.
So we didn’t use the hairpin method, but we also didn’t use a clustered setup for any of our mail system components. And when you decide to eat your own dog food, you better present it as a grand buffet.
Our new clustered email system is spread out over three data centers and consists of these components:
- Virtual machines (KVM, libvirt, Azure)
- Four LDAP servers (OpenLDAP)
- Two mail servers (Postfix, Dovecot, Rspamd)
- Two HTTP load balancers (NGINX)
- Three CipherMail Gateway nodes
- Three CipherMail Webmail nodes
We cheated a little here as the third data center is only used for MariaDB Galera arbitrating. The Galera databases of the Gateway and Webmail nodes need an uneven number of MariaDB servers to achieve quorum, which is essential to the voting system used to maintain database consistency.
We turned to the DebOps project for the orchestration of the whole setup. DebOps is a set of free and open source tools for managing Debian-based data centers, and is founded on the Ansible configuration management system. We have been using DebOps to automate almost everything in our IT infrastructure over the course of the last eighteen months.
We use the libvirt API and virt-manager to manage virtual machines. The libvirt daemon, as well as network and (NFS) storage configuration, is managed by the debops.libvirtd and debops.libvirt roles. Using NFS for shared storage between our hypervisors makes live migrations possible, which allows for hypervisor maintenance without downtime. The virtual machines at Azure are managed with a custom Ansible role.
The LDAP cluster uses multi-master replication as provided by the debops.slapd role. It stores things like users, groups, service accounts and domain names and is extensively used by our mail servers. The information in our LDAP database defines which mailboxes are present on our servers, which credentials are needed to access them, what email addresses a user is allowed to send mail from, where (group) mail should be forwarded to, and which automated systems are allowed to relay mail through our servers.
Our two mail servers are managed with the Dovecot and Postfix roles that are part of DebOps. We wrote a custom role to manage the Rspamd filter.
We made a few customizations to the Postfix roles in the form of Ansible inventory variables that define additional configuration options. These are the content filter (which forwards all mail to the CipherMail Gateway nodes after queueing) and the services responsible for receiving mail from CipherMail Gateway and Webmail. These services, the so-called re-injection ports, accept all mail from the Gateway and Webmail nodes, but have the content filter configuration removed to ensure that mail is actually delivered this time and an infinite loop cannot occur.
The Dovecot role is amended with sieve mail filtering support (think automated mail sorting and out-of-office messages) as well as mail replication through dsync. These modifications were possible without having to change the underlying DebOps role, again thanks to the role flexibility and Ansible inventory variables. Mail replication with dsync is especially useful as it makes your IMAP server highly available. There is little configuration required and works without any maintenance once it’s set up. CipherMail Webmail also uses dsync to sync mail between cluster nodes.
The HTTP load balancers are nothing fancy, just two NGINX servers that perform load balancing for https://webmail.ciphermail.com/. We went with the debops.nginx role for this because of its completeness and ACME (Let’s Encrypt) support, which also works when you use two NGINX servers. The ip_hash load balancing method ensures that clients always end up using the same Webmail node (unless that node is not available). This is important because otherwise sessions and attachment uploads might break, as these are not replicated between CipherMail Webmail nodes.
CipherMail Gateway and Webmail, while easy to use and straightforward to configure both standalone and in a cluster setup, currently do not come with a ready-to-use automation system. This makes installation and maintenance less efficient than it could be. Actually installing, maintaining and using our own CipherMail clusters brought this to light, and we are now exploring ways to make use of automaton tools in our products so that installations and upgrades are as simple as running an Ansible playbook, and whole clusters can be deployed in one go.
Putting everything together, our current email infrastructure looks like this:
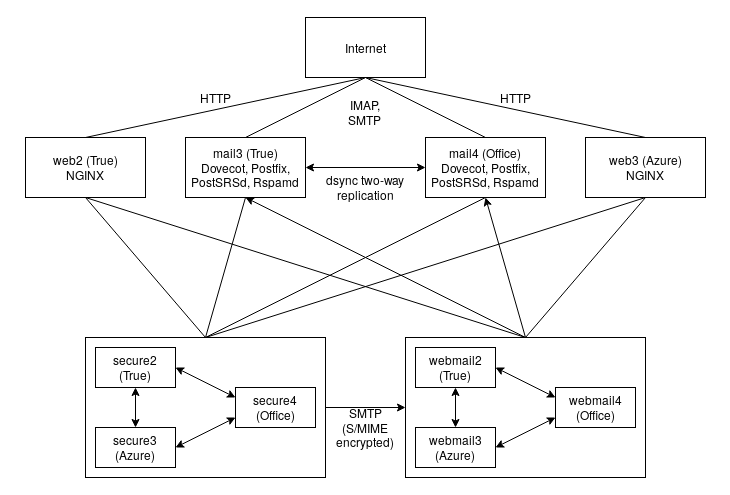
This may be overkill if you consider the amount of email we actually process with this setup, but we consider it necessary in order to better test and improve the software we write, as well as demonstrating confidence in the solutions we provide to our customers. We are eating our own dog food.
If this article made you interested in our products, please contact Us for a demo, or try out the open source community edition yourself. You can find more information about DebOps and its awesome community on the documentation website as well as the GitHub repository. The custom roles that we wrote and are currently integrating with DebOps can be found on our GitLab page.